Added utilities to instrument kernel bandwidth numbers (#95355)
Looks like
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95355
Approved by: https://github.com/ngimel, https://github.com/jansel
diff --git a/torch/_inductor/codegen/wrapper.py b/torch/_inductor/codegen/wrapper.py
index 688ac57..decb19f 100644
--- a/torch/_inductor/codegen/wrapper.py
+++ b/torch/_inductor/codegen/wrapper.py
@@ -289,7 +289,7 @@
"""
import triton
import triton.language as tl
- from torch._inductor.triton_ops.autotune import grid
+ from torch._inductor.triton_ops.autotune import grid, start_graph, end_graph
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
"""
)
@@ -504,6 +504,9 @@
"with record_function('inductor_wrapper_call'):"
)
stack.enter_context(self.wrapper_call.indent())
+ if config.profile_bandwidth:
+ self.wrapper_call.writeline("start_graph()")
+
while (
self.lines
and isinstance(self.lines[-1], MemoryPlanningLine)
@@ -536,6 +539,10 @@
output_refs = self.get_output_refs()
if config.triton.debug_sync_graph:
self.wrapper_call.writeline("torch.cuda.synchronize()")
+
+ if config.profile_bandwidth:
+ self.wrapper_call.writeline("end_graph()")
+
self.generate_return(output_refs)
self.append_precomputed_sizes_to_prefix()
diff --git a/torch/_inductor/config.py b/torch/_inductor/config.py
index fa87b37..2903f77 100644
--- a/torch/_inductor/config.py
+++ b/torch/_inductor/config.py
@@ -125,6 +125,11 @@
# used for debugging to make sure config is properly set
_raise_error_for_testing = False
+_profile_var = os.environ.get("TORCHINDUCTOR_PROFILE", "")
+profile_bandwidth = _profile_var != ""
+profile_bandwidth_regex = "" if _profile_var == "1" else _profile_var
+
+
# config specific to codegen/cpp.pp
class cpp:
# set to torch.get_num_threads()
diff --git a/torch/_inductor/triton_ops/autotune.py b/torch/_inductor/triton_ops/autotune.py
index f1075f5..5c4d9e2 100644
--- a/torch/_inductor/triton_ops/autotune.py
+++ b/torch/_inductor/triton_ops/autotune.py
@@ -2,9 +2,11 @@
import copy
import functools
import hashlib
+import inspect
import json
import logging
import operator
+import os
import os.path
import re
import threading
@@ -204,6 +206,76 @@
return result
+def _find_names(obj):
+ import gc
+ import inspect
+
+ frame = inspect.currentframe()
+ for frame in iter(lambda: frame.f_back, None):
+ frame.f_locals
+ obj_names = []
+ for referrer in gc.get_referrers(obj):
+ if isinstance(referrer, dict):
+ for k, v in referrer.items():
+ if v is obj:
+ obj_names.append(k)
+ return obj_names
+
+
+collected_calls = []
+
+
+def start_graph():
+ collected_calls.clear()
+
+
+def end_graph():
+ if len(collected_calls) == 0:
+ return
+ overall_time = sum(call[1] for call in collected_calls)
+ overall_gb = sum(call[2] for call in collected_calls)
+ cur_file = inspect.stack()[1].filename
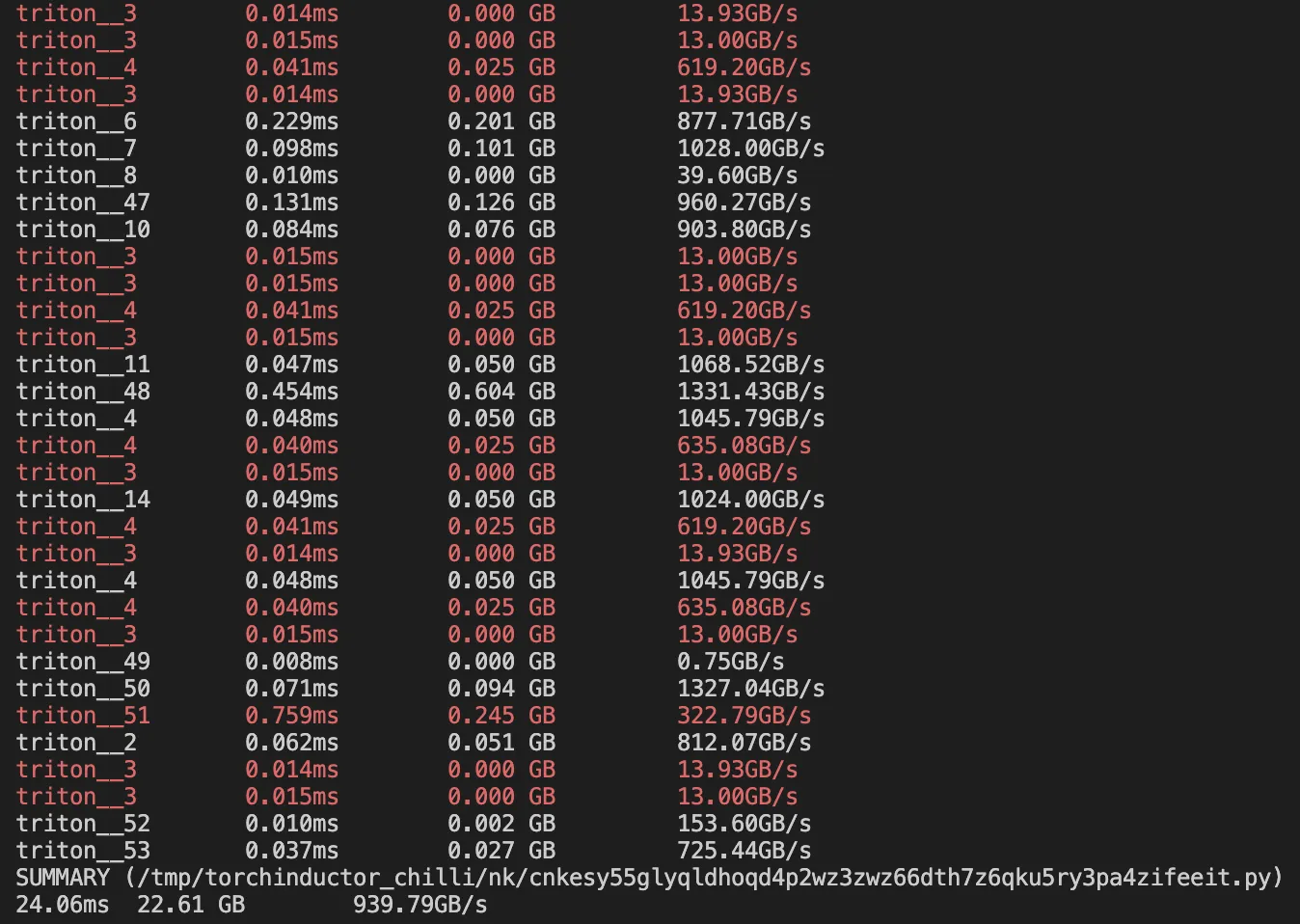
+ print(f"SUMMARY ({cur_file})")
+ print(
+ f"{overall_time:.2f}ms\t {overall_gb:.2f} GB\t {overall_gb/(overall_time/1e3):.2f}GB/s"
+ )
+ print()
+
+
+class DebugAutotuner(CachingAutotuner):
+ def __init__(self, *args, regex_filter="", **kwargs):
+ self.regex_filter = regex_filter
+ super().__init__(*args, **kwargs)
+
+ def run(self, *args, grid, stream):
+ possible_names = _find_names(self)
+ kernel_name = f"{max(possible_names, key=lambda x: len(x))}"
+ if not re.match(self.regex_filter, kernel_name):
+ return
+ super().run(*args, grid=grid, stream=stream)
+ (launcher,) = self.launchers
+
+ def get_num_bytes(*args):
+ return sum(
+ arg.numel() * arg.element_size()
+ for arg in args
+ if isinstance(arg, torch.Tensor)
+ )
+
+ ms = self.bench(launcher, *args, grid=grid)[0]
+ num_gb = get_num_bytes(*args) / 1e9
+ gb_per_s = num_gb / (ms / 1e3)
+
+ collected_calls.append((kernel_name, ms, num_gb, 1e3 * num_gb / ms))
+ import colorama
+
+ info_str = f"{kernel_name}\t {ms:.3f}ms\t{num_gb:.3f} GB \t {gb_per_s:.2f}GB/s"
+ if ms > 0.012 and gb_per_s < 650:
+ print(colorama.Fore.RED + info_str + colorama.Fore.RESET)
+ else:
+ print(info_str)
+
+
def hash_configs(configs: List[Config]):
"""
Hash used to check for changes in configurations
@@ -273,6 +345,15 @@
mutated_arg_names = meta.pop("mutated_arg_names", ())
def decorator(fn):
+ if config.profile_bandwidth:
+ return DebugAutotuner(
+ fn,
+ meta=meta,
+ regex_filter=config.profile_bandwidth_regex,
+ configs=configs,
+ save_cache_hook=save_cache_hook,
+ mutated_arg_names=mutated_arg_names,
+ )
return CachingAutotuner(
fn,
meta=meta,
{kind=link}